


Risk is inherent in business. By operating in the market place, offering products or services to the public, processing transactions or storing data, companies large and small face risk, and increasingly that’s cyber risk. The question is, how do these companies decide whether to accept or respond to risks?
Qualitative Risk Analysis
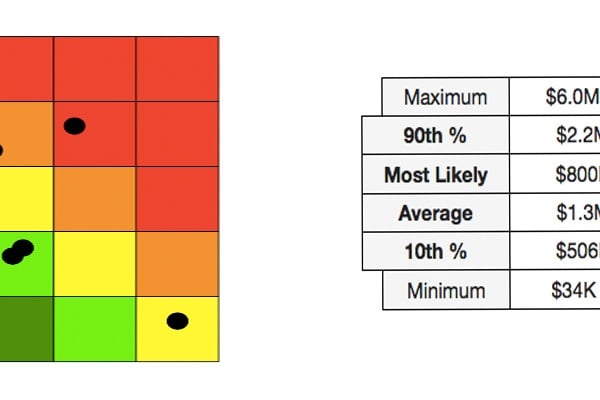
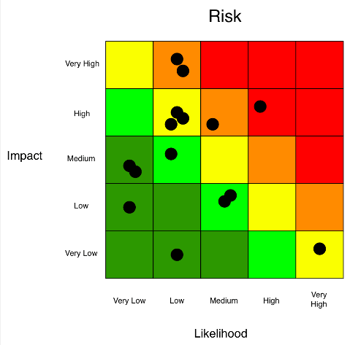 In practice, qualitative risk analysis is the process of using ordinal (1-5 or green, yellow, red) rating scales to plot various risks based on their frequency (likelihood of occurrence) and magnitude (impact of loss) to the organization. By doing so, organizations are able to visually represent the relative severity of the various risks the organization faces.
In practice, qualitative risk analysis is the process of using ordinal (1-5 or green, yellow, red) rating scales to plot various risks based on their frequency (likelihood of occurrence) and magnitude (impact of loss) to the organization. By doing so, organizations are able to visually represent the relative severity of the various risks the organization faces.
Although the scales allow for a risk-by-risk categorization, there are several fundamental flaws. The first relates to consistency. With purely qualitative measurements, there is a higher probability that the person doing the measurement hasn't taken the time to clearly define what it is they just measured. In other words, they tend to be highly reliant on an ambiguous mental model of risk.
In addition to the lack of consistency, there is also a greater tendency to inflate risk. This stems from the idea of “better safe than sorry.” If you are uncertain if a risk is yellow or red, it is “safer” to categorize it as red to err on the side of accounting for the maximum amount of risk. Besides, very often it's only the "red risks" that get any attention, so if I feel like something needs to be addressed I have to label it as red/high.
Another issue lies with risk prioritization and mitigation. When there are multiple red risks, how do you decide which to mitigate first? Which one is "reddest"?
While qualitative risk analysis is efficient, suited to quick decisions, and easy to communicate (with a pretty heat map), the drawbacks associated with it are bias and inconsistencies in risk analysis, and ambiguity in meaning (what does "red/high" really mean?).
And many questions relating to prioritization and resource allocation such as "how much risk do we have?", "are we spending too much or too little?" cannot be answered this way.
Quantitative Risk Analysis
 Contrary to qualitative risk analysis, quantitative risk analysis reduces the tendency toward bias and inconsistencies when coupled with a well-defined model to evaluate risk. Further, it addresses the prioritization problem by utilizing economic terms – dollars and cents – as its measurement, rather than an ordinal or relative scales.
Contrary to qualitative risk analysis, quantitative risk analysis reduces the tendency toward bias and inconsistencies when coupled with a well-defined model to evaluate risk. Further, it addresses the prioritization problem by utilizing economic terms – dollars and cents – as its measurement, rather than an ordinal or relative scales.
The leading quantitative cyber risk analytics model is FAIR or Factor Analysis of Information Risk. FAIR takes the two axes of a heat map – frequency and magnitude – and further breaks them down into component parts which can be measured as losses by subject matter experts (for instance, cost of paying for credit monitoring services for customers affected by a data breach). By using a structured model to evaluate risk, FAIR helps to ensure that the same rigorous and consistent approach is used across analyses, as such, allowing them to be accurately compared.
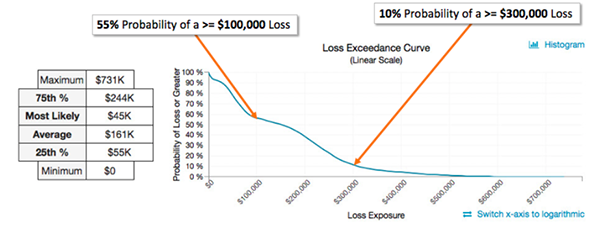
To account for uncertainty and improve accuracy, FAIR utilizes distributions for inputs rather than static values. These distributions allow for an accurate range with a useful degree of precision.
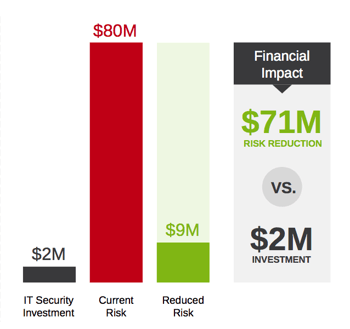
The output of a quantitative risk analysis using FAIR results in both a bell curve and loss exceedance curve showing a range of probable loss exposure outcomes for the given risk(s). The analysis can be re-run for an anticipated future state to compare loss exposure with the application of controls, to understand a return on investment.
Additionally, the flexibility of economic measurement allows for the results to be translated back into a heat map representation for easy communication of the probable losses among a group of risks. Only this time, when you are asked how you came up with the risk rating, you will have a rigorous approach backed by a standardized model utilizing accurate distributions to defend your answer.
Related:
Is Cyber Risk Measurement Just Guessing?
Gartner Endorses Risk Quantification as Critical to Integrated Risk Management






