


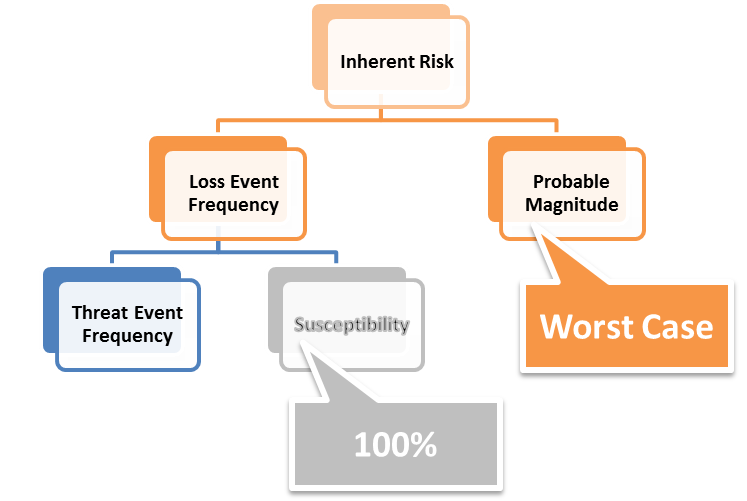
During the February meeting of the FAIR Institute's Operational Risk workgroup, members discussed the ever popular concept of “inherent risk” and how it could be best used in the context of a standard risk methodology like FAIR. Inherent risk is commonly defined as “the amount of risk that naturally exists prior to considering any controls.” Building on an earlier post by Jack Jones, the group explored how FAIR’s ontology might be used to approximate the two most common uses of inherent risk:
- Driving the prioritization of assessment efforts
- Deriving residual risk, after applying existing control effectiveness
Inherent risk is an attempt to describe the importance of a business process or resource, essentially sizing the potential loss exposure generically. This abstract (and arguably artificial) concept doesn’t look at any one category of risk alone, or any single loss scenario, but rather tries to rank the potential loss exposure across all types of risk relative to other processes/resources. This ranking might inform assessment planning for the year, determine how deep of an assessment to perform, prescribe whether an onsite review of a third-party is required, etc. In our quest to perform our risk management responsibilities in a cost effective and efficient manner, this seems like a helpful concept … we’ll come back to this.
The second use of inherent risk is really just a step along the way to determine residual risk. Typically, an inherent risk is determined (sans controls), then control effectiveness is separately assessed or tested, and then the two are combined to derive the residual risk. There are several challenges with this approach. The first is that you can never really consider risk exposure without any controls. There are so many controls that are already baked into the organization or environment, that one really can’t strip them all away. Even with a brand new venture or project, this is difficult to conceptualize. Another challenge is that the typical inherent risk is a mashup of many disparate scenarios all combined into one rating. Then a set of controls are assessed, generating another separate rating, and these are combined. However, not all the controls assessed are even relevant to each of the scenarios implied in the original inherent risk rating. So you end up with a very shaky connection between the two.
So how might FAIR help? One approach the workgroup discussed was leveraging the Susceptibility factor (also referred to as Vulnerability) in the FAIR ontology to approximate the concept of risk without controls.
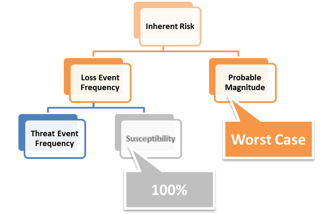
Essentially what you’re doing is forcing the threat events to be 100% successful, and assuming the worst case for probable magnitude. In other words, you’re assuming that every natural opportunity for a loss event is successful. This gives us enough information to make our initial risk assessment prioritization decisions.
Next, we need to apply the “control effectiveness” to derive residual risk. Applying the concept back to the FAIR ontology, control effectiveness can be represented as the inverse of the Susceptibility factor. For example, you could represent control effectiveness (i.e. susceptibility) ratings using the following ranges of probability:

Using this example, stronger controls means a lower probability of threat success. Weaker controls indicate a higher probability of threat success. If the given control operates as expected only 2 out of 3 times, then it would be labeled as “Average” in this example.
One of the advantages of this approach is that it clarifies how different controls will change the resulting residual risk exposure. By categorizing the controls, each can be related to a separate factor in the FAIR ontology:
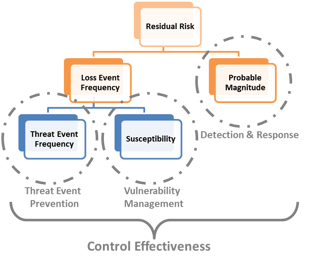
For example, applying additional detection controls will lessen the probable magnitude, but doesn’t change the loss event frequency. Conceptualizing it in this way should help inform which levers you can pull, and most effectively mitigate risk to an acceptable level.
Recognizing that inherent risk is a ubiquitous concept for operational risk professionals, we can overcome some of its limitations by structuring it around the FAIR ontology and adjusting the definition slightly. The result may be a useful tool. However, proceed with caution. There are many poor implementations of the inherent risk concept in common practice, and often too much reliance on the results. If you’re in a position to consider an alternative to inherent risk, experiment with representing risk as the current state, with variations of future-state based on treatment decisions that could be made. Or explore using Jack’s suggestion of redefining it as “the amount of risk that exists when key controls fail.”
If you found this topic interesting and would like to participate in future discussions, please consider joining the FAIR Institute’s Operational Risk workgroup. A recap of this call is available for on-demand viewing in the Member Resources Center. The next call is on February 28th at 4:00 pm ET.

-squared-1.png)
.png)



