


 In my last blog post on qualitative risk measurement, I discussed three key aspects that often make the difference between good measurements and bad measurements — scope, model, and data. I also pointed out that these apply to both qualitative and quantitative risk measurement.
In my last blog post on qualitative risk measurement, I discussed three key aspects that often make the difference between good measurements and bad measurements — scope, model, and data. I also pointed out that these apply to both qualitative and quantitative risk measurement.
However, there’s a related topic that needs to be covered as well, which is unique to qualitative measurements — measurement scales. These too, can spell the difference between reliable and unreliable risk measurements.
This post is Part 3 of the series Jack Jones on Qualitative vs Quantitative Risk Measurement.
Jack Jones is Chairman of the FAIR Institute and creator of FAIR™ (Factor Analysis of Information Risk), the international standard for quantitative risk analysis, introduced in the book Measuring and Managing Information Risk. Jack recently released FAIR-CAM™, the FAIR Controls Analytics Model™.
Training on FAIR is available through the FAIR Institute.
We’re all familiar with qualitative labels like High, Medium, and Low, but what do they mean? How do they relate to reality from a measurement perspective?
Let’s use a number line that represents the potential impact from a cybersecurity event. On the far left we have $0 impact, and on the far right we have the net worth of the company. This captures the entire range of possible outcomes (from the company’s perspective) from a loss event.

We could make the same sort of line with the likelihood component of risk, only that line would run from 0% chance of an event occurring within a given period to 100% certainty of it occurring in that time frame.
Now we carve up that range of impact using a common 5-level qualitative scale. Nice and neat, yes?

The problem is, in most organizations the definitions for each level of the scale aren’t at all clear — they’re made up of verbiage that usually consists of subjective, qualitative terms like “substantial loss.” As a result, the people who are rating impact won’t have a nice, neat rating scale in their heads. They’ll have something like this:

[Harvard Business Review: If You Say Something Is Likely, How Likely Do People Think It Is?]
And do you remember from my last post, that circumstance where you’re arguing with someone about whether something is High, Medium, or Low risk, and I said that scope, model, and data were likely culprits for your differences? Well, this makes it even worse because one of you has the scale above in mind, while the other person’s scale looks like this:

If organizations want to meaningfully improve their qualitative measurements, they need to ensure their measurement scales are as clearly defined as possible (as well as ensure the scope, model, and data issues I discussed in my earlier post are addressed). With that in mind, what does a clear qualitative measurement scale for impact look like? Here’s an example scale that I’ve seen used with success in the past:
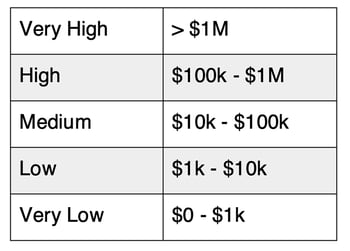
NOTE: The values for each level in the scale will often vary by an organization’s size and risk appetite. Obviously, this has some limitations and challenges with it too, but it’s far less ambiguous and problematic than the usual scale definitions organizations use.
On a number line that scale would look something like this.
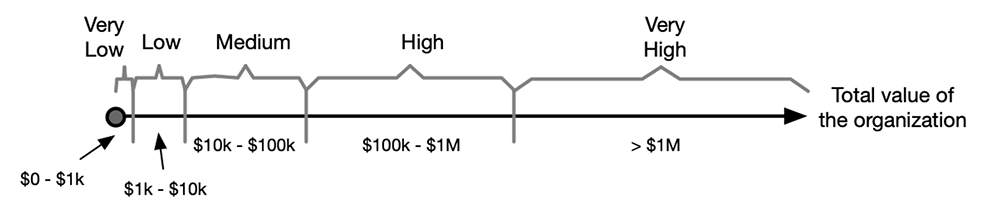
Note that it’s a log scale (not drawn to scale), which has some important implications I’ll discuss in a future post. It’s also, ahem, a quantitative scale that’s simply been parsed into ordinal categories of loss. The same sort of thing can be done for a frequency/likelihood scale.
The bottom line on qualitative risk measurement
 A risk management program cannot be considered mature or effective if it can’t reliably measure risk.
A risk management program cannot be considered mature or effective if it can’t reliably measure risk.
And here’s some additional food for thought — which maturity model in our industry accounts for ANY of the points I’ve discussed in these two posts? None that I’m aware of. They all call for risk measurement and prioritization to take place, and then assume that it’s going to be done well. Clearly, this is a missed opportunity to fundamentally improve the efficacy of risk management programs.
Is it possible to do good qualitative measurement? Yes. But as a rule, that’s not what happens. And because most organizations aren’t aware of these deficiencies, they muddle along prioritizing poorly and then we wonder why we keep having our clocks cleaned by cyber criminals. But hey, at least bad qualitative risk measurement is easy, right?






