About Us
Leadership
Founder and Advisor
Awards
Contact Us
Research & Standards
Standards Committee
Working Groups
Learn FAIR™
Training and Certification
WHAT IS FAIR?
FAIR RISK MANAGEMENT
AUTOMATING FAIR
FAIR-CAM
FAIR-MAM
AI Risk with FAIR
FAIR FAQ
Resources
Resource Library 🔐
Blog
How Material is that Hack
FAIR Book
FAIR-U Workbook (beta)
Partners
Founder and Advisor
Sponsors
Education Partners
FAIR For Academia
Get Involved
Individual Membership
Corporate Membership
FAIR Conference
Upcoming Events
Local Chapters
Get Involved
Search
FAIR Institute blogs
FAIR Framework
A FAIR Framework for Effective Cyber Risk Management
Resource Center
Members Only
Explore
Subscribe for updates
Resource Center
Members Only
Explore
Subscribe for updates
View All
Events
Fair Institute
Government
Guides & Tips
Member Content
Risk Management
All Posts
View All
Events
Fair Institute
Government
Guides & Tips
Member Content
Risk Management
All Posts
Interested in becoming a FAIR member?
CTA Text
Interested in becoming a FAIR member?
[ PLACEHOLDER FOR IMAGE ]
[ PLACEHOLDER FOR CTA ]
CTA Text
FAIR
Inherent Risk vs. Residual Risk Explained in 90 Seconds
FAIR
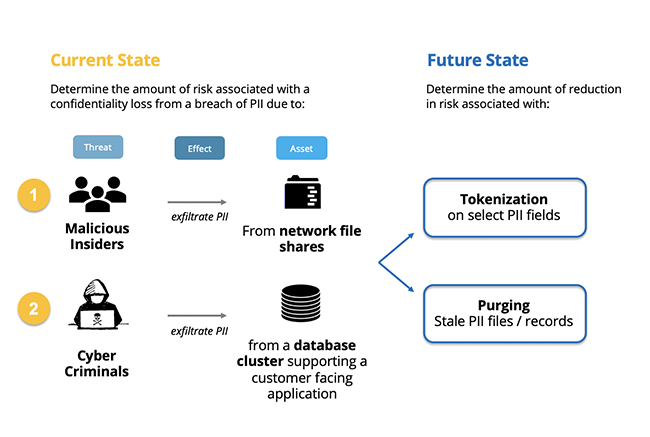
Evaluating Data Retention Risk from GDPR Using FAIR
FAIR
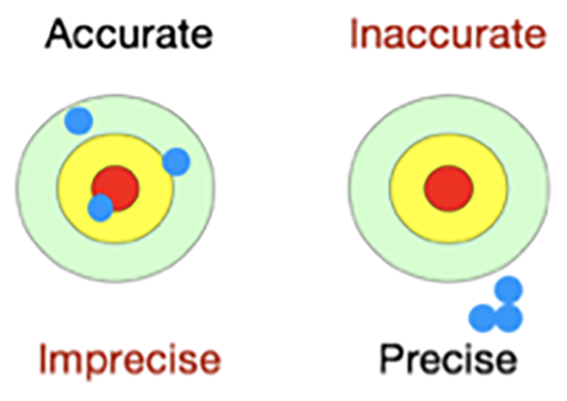
Cure Your Risk Analysis Paralysis: Balance Accuracy and Precision
FAIR
Banks Move to FAIR for FFIEC CAT Cybersecurity Risk Assessments
FAIR
The Skeptic's Guide to Cyber Risk Surveys
FAIR
For Better Risk Assessments in SSAE 18 Audits, Try Quantification with FAIR
Risk Management
How to Analyze Your Risk from GDPR: A FAIR Approach