


A recent survey of security and risk management executives by the leading tech consultancy Gartner -- Benchmarking Cyber-Risk Quantification – finds widespread planning and adoption of cyber risk quantification (CRQ) but also points out confusion in the marketplace as to what exactly is CRQ.
Here are the top-line numbers. A whopping 80% adoption of “Less Sophisticated” CRQ methodology!
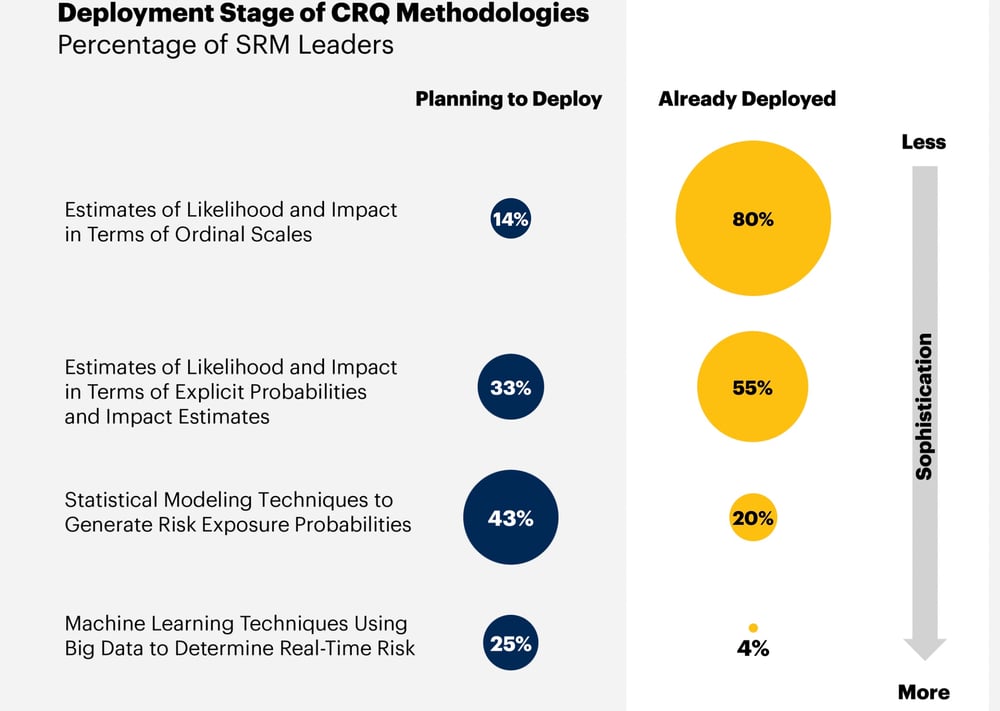
But wait. “Estimates of likelihood and impact in terms of ordinal scales” do not CRQ make. As Jack Jones, creator of Factor Analysis of Information Risk (FAIR™), the international standard for quantification of cyber, operational and other forms of risk, wrote in his CRQ Buyers Guide.
Although this approach uses numeric values, we have to recognize that 1-thru-5 (and similar) scales are ordinal values that can be replaced with words (e.g., High, Medium, Low) or colors (e.g., red, yellow, green). Therefore, numeric scales like these are not quantitative values but instead represent labels for “buckets” that permit high-level grouping and ordering (thus the term “ordinal”).
In short, grouping not estimating, the true use of CRQ. Here’s Jack’s basic requirements for CRQ from the Buyer’s Guide:
Loss event probability is expressed as a percentage (e.g., 10% probability of occurrence in the next 12 months) and magnitude is expressed as a loss of monetary value (e.g., $1.5M). When desired, these values can be combined to express risk as an annualized amount (e.g., $150,000).
The next two CRQ adoption types in the survey – “estimates using explicit probabilities and impact estimates” (55% deployed) and “statistical modeling techniques to generate risk exposure probabilities” (20% deployed) – could describe systems using FAIR and let’s hope they do, as FAIR is the only model for CRQ that’s been vetted and maintained as an open standard by a respected third-party professional organization, The Open Group. Alternatives are black box models, as Jack explained in the blog post, FAIR vs Proprietary Cyber Risk Analysis Models:
 They could be great or worthless, but users can’t be sure, and they can’t push back. For instance, we don’t know what assumptions went into the model… I consider open vs. proprietary risk analysis models to be analogous to proprietary vs. open cryptography; researchers settled long ago that proprietary cryptography is a bad idea because there are so many (and subtle) ways it can go wrong. The very same thing is true for quantitative risk analysis.
They could be great or worthless, but users can’t be sure, and they can’t push back. For instance, we don’t know what assumptions went into the model… I consider open vs. proprietary risk analysis models to be analogous to proprietary vs. open cryptography; researchers settled long ago that proprietary cryptography is a bad idea because there are so many (and subtle) ways it can go wrong. The very same thing is true for quantitative risk analysis.
The ultimate deployment stage Gartner considers is “machine learning techniques using big data to determine real-time risk” (4% adoption). AI + cyber risk management, it’s the cybersecurity moonshot that everyone wishes for. Here again, a caution. As Jack writes,
3 things are required for accurate CRQ (whether automated or not):
>>A clear scope of what’s being measured — e.g., the asset(s) at risk, the relevant threat(s), the type of event (outage, data compromise, fraud, etc.).
>>An analytic model (e.g., FAIR), which identifies the parameters needed to perform the analysis, and how data are used to generate a result.
>>Data, which can (ideally) be empirical data, or simply subject matter expert estimates.
On the surface, these don’t sound too intimidating, but all three need to be done well to get accurate results. And that isn’t as easy as one might imagine.
Read his blog post series Automating Cyber Risk Quantification for details.
At the 2022 FAIR Conference, RiskLens previewed a tool that automates CRQ following Jack’s three points plus the methodology of his FAIR Controls Analytics Model that accounts for the interrelationships of cybersecurity controls in risk management.
Regardless of how effectively the survey respondents implement CRQ at this stage, the Gartner report shows an appetite for quantification that’s a hopeful sign. Seventy-eight percent use it to prioritize risks and 46% are trying to tie risk analysis with business action, though they still find that challenging.

-squared-1.png)
.png)



