



 In the first post of this series, I focused on answering a commonly expressed concern about the reliability of cyber risk measurement. At the end of that post, I mentioned that some readers might draw a distinction between an example I gave and the real world of cyber risk measurement.
In the first post of this series, I focused on answering a commonly expressed concern about the reliability of cyber risk measurement. At the end of that post, I mentioned that some readers might draw a distinction between an example I gave and the real world of cyber risk measurement.
One of the objectives of this post is to describe the realities surrounding risk measurement that make moot any concerns regarding whether my example was too different from the risk world.
More importantly, I want to put to rest the fallacy that a qualitative “gut” measurement is better than a quantitative one and/or that you "can't quantify cyber risk".
You can’t avoid measurement
I have yet to encounter a professional in our field that hasn’t agreed with these statements:
- The cyber risk landscape is complex and dynamic, and our resources for managing it are limited.
- Because of the first point, we are forced to prioritize what we focus on, and we need to choose the most cost-effective solutions for the things we choose to focus on.
- Prioritization and solution selection inherently involve comparisons, and comparisons always involve some form of measurement.
If you have a rational argument against any of these points, I’d love to hear it. Otherwise, we logically agree that measurement is unavoidable.
What does measurement accomplish?
As Douglas Hubbard states so well in his writings — the purpose of measurement is to reduce uncertainty. For example:
Let’s say we need to know how much risk a deficient control represents so that we can prioritize it properly and/or choose a cost-effective treatment. Let’s also say the answer we’re given by someone is that it represents “medium risk”. Yes, that is a measurement because before the answer was given, there was complete uncertainty — i.e., the range of possible levels of risk was unbounded. Now we know that it’s “medium risk” (or the person providing the answer believes it’s “medium”). At the very least, if we ascribe to the notion that the continuum of risk (from zero to infinite) can be parameterized into three buckets (or five, if you prefer) — high, medium, and low — we now know which bucket that deficient control falls into, which represents a reduction in uncertainty.
Of course, unless “medium” is clearly defined there’s still a tremendous amount of uncertainty — but let’s put a pin in that for the moment. I just wanted to use the example above to demonstrate how even something as simple as a qualitative risk rating satisfies the definition of measurement.
Some things are easier to measure than others
At the easy end of the measurement spectrum are things that can be measured directly (a single value like distance) — i.e., they’re not complex. At the harder end of the continuum are things that can’t be measured directly but instead have to be derived from two or more parts (e.g., speed being derived from measurements of distance and time). The more parts involved (higher complexity), the more sub-measurements required in order to arrive at the thing you’re actually trying to measure and reduce uncertainty about.
Besides the challenges that come with having to deal with multiple sub-measurements, complex measurements add something else to the mix — you need a model in order to combine the data points. For example, the speed = distance / time equation is a model. The more data points involved, the more complex the model.
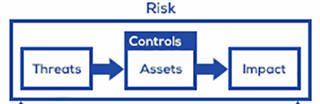
Risk obviously falls well into the complex end of the spectrum because it’s derived from many factors. (e.g., asset value/liability, control conditions, threat variables, etc.). Not only that, but many of the cyber-related data points can be highly dynamic (depending on the risk scenario). And, of course, a model is necessary to combine those data points.
Criteria for good measurement

Good measurements are accurate and have a level of precision that is useful and that faithfully represents the level of (un)certainty in the measurement. But what factors contribute to a cyber risk measurement that fits this description? That, too, is pretty simple — the quality of the data and how the data is applied to the models being used (e.g., through the use of ranges to represent uncertainty). Note that “models” is plural…
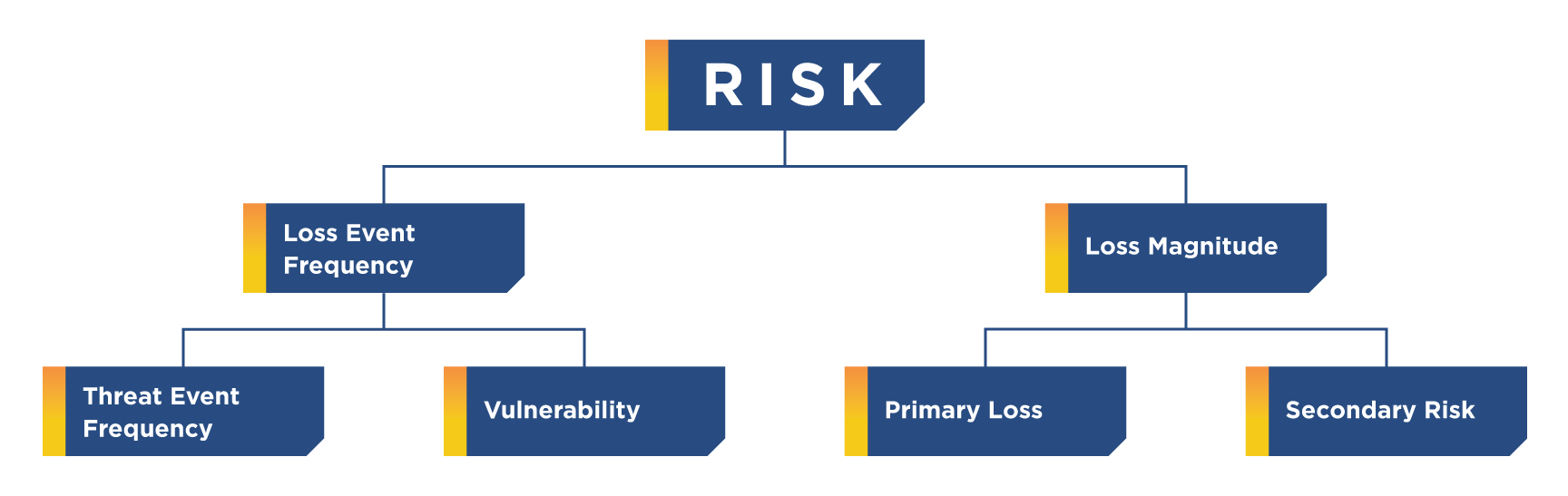
When measuring risk, you actually need to use two models — a model of the factors that make up risk (which is what FAIR provides), and a model of the risk landscape elements that make up the scenario (the relevant asset(s), threat(s), and controls).
The bottom line here is that the better your data and models are, the better your measurement is going to be.
Where should we place our faith in cyber risk measurement?
As critics love to point out, very often we don’t have much hard data when measuring cyber risk. In fact, sometimes we have to rely solely on subject matter expert estimates. They’re right. What they never admit or seem to recognize though, is that this constraint applies equally to qualitative measurements.
But wait — there’s more. When someone uses their gut/expertise to qualitatively rate something as high/medium/low risk, invariably they are using their own mental model of risk, plus an informal (and usually not clearly defined) mental model of the scenario elements that are in play, plus whatever informal data is stored in their memory. Not exactly a recipe for reliable reduction in uncertainty.
In the interest of keeping this post no longer than necessary, I’m going to wrap up with this — I cannot imagine a logical/rational argument that successfully makes a case that informal qualitative risk measurement is better than measurement based on:
- A formal model of risk that’s been poked and prodded at for over a dozen years (the FAIR model)
- A clearly defined scenario model, which anyone trained in FAIR is going to create before measuring anything
- Data that has been arrived at through a process that leverages hard data when available, and calibrated subject matter expert estimates when hard data isn’t available. (If you aren’t familiar with calibrated estimates, you should read Douglas Hubbard’s best-selling book, How to Measure Anything.)
 Qualitative risk measurements are not based on better data — they’re typically based on worse, and almost always with less reliable models.
Qualitative risk measurements are not based on better data — they’re typically based on worse, and almost always with less reliable models.
It’ll be interesting to see the comments this post gets (if any). Will someone fall back on the usual — “But everyone knows you can’t measure cyber risk” or "But there isn't enough data" — or will they actually apply some grey matter and offer a logical set of rationale? Or maybe someone will suggest that qualitative measurements are good enough and that quantification isn’t meaningfully better. Well, if those qualitative measurements are based on strong models and data that’s thoughtfully arrived at, and if the ordinal scales being used are very clearly defined, then yes and no. But that’s a topic for another day...
To learn more about the FAIR model and risk quantification – and to participate in live webinars with Jack Jones – join the FAIR Institute. Membership is free.






