



 This 5th post in this series comes to you courtesy of useful feedback I received from leaders within the NIST CSF program team. They had read the first four posts in this series and wanted to clarify a couple of points. We also agreed that a 5th post (this one) might be a good idea to flesh out some thinking on the second point below.
This 5th post in this series comes to you courtesy of useful feedback I received from leaders within the NIST CSF program team. They had read the first four posts in this series and wanted to clarify a couple of points. We also agreed that a 5th post (this one) might be a good idea to flesh out some thinking on the second point below.
Based on their clarifications I’ve made two changes to the 2nd post in the series. If you’ve already read that post you don’t need to go back and re-read it, as the changes simply boil down to:
- The NIST CSF framework is intended to be adaptable — i.e., organizations are expected to build “profiles” from the NIST CSF sub-categories that specifically address their unique cyber security needs. In other words, some organizations might exclude some sub-categories from an evaluation because those sub-categories aren’t considered relevant to them. This implies, too, that organizations could add sub-categories that they view as missing from the framework but that they view as relevant. This flexibility seems reasonable given variances in risk landscapes across industries, etc., but it makes benchmarking using the framework more difficult. Unless, of course, standard profiles are defined for each industry.
- Despite common interpretation to the contrary, the four NIST CSF tiers are NOT intended to be used for measuring the condition of sub-categories — e.g., you wouldn’t try to rate “DE.AE-2 (detected event analysis)” using the four tiers described within the framework. Instead, organizations are expected to define and use their own measurement scales. The advantage is better utility than the current NIST CSF tiers provide. The disadvantage is that this limits the ability to benchmark using NIST CSF.
Measurement scale challenges
The second point above is both good news and bad news. Clearly, the existing tiers are not useful as a measurement scale for sub-categories, so it’s important that organizations quit trying to fit that square measurement peg into the round sub-category holes. So the good news is that NIST wasn’t expecting the tiers to be used that way.
The “bad” news is twofold:
- The ability to benchmark is limited when scales vary from organization to organization
- Our industry doesn’t typically do a good job of defining measurement scales
Too often, measurements in assessment frameworks are binary “yes/no” when there are actually relatively few conditions that can accurately be described as only either completely in place or completely missing. When someone is faced with choosing a “yes” or “no” answer for a condition that’s isn’t binary in nature, they have to choose whether to give zero or full credit. Either option is inaccurate and thus misleading.
There are also inherent limitations even when a more nuanced ordinal scale is used (e.g., 1 thru 5). For example, if an organization describes its “Detected event analysis” capabilities as being at a “3” level, what does that actually mean? What’s the real difference between a 3 and a 4 in that capability, or a 2 for that matter? Without pretty clear differentiation, there is simply too much room for subjectivity and bias. Furthermore, even if differentiation in levels is clear, how much confidence should there be in that rating. Is the rating simply someone’s wet finger in the air or is there something to back it up?:
This confidence dimension is pretty important because there can be a big difference in efficacy between an organization that has validated its risk management capabilities versus one that “thinks” it’s at a 3 (or whatever) level.
Something a bit more useful
A very simple solution that I’ve used to good effect is two-dimensional. It uses a three-level capability rating scale (“Weak”, “Partial”, “Strong”), and a three-level “confidence” (or maturity) rating scale (“Unsubstantiated”, “Substantiated thru policies and/or processes”, “Validated thru testing”). We’ll get into definitions for these in a minute, but here’s what a matrix view of the scoring would look like:
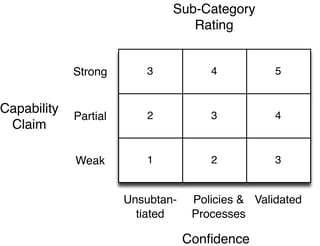
As you can see, Confidence is given the same weight as Capability. For example, an organization with Partial capability in some sub-category (e.g., Detected event analysis) is given credit if it has policies and/or processes that help to ensure event analysis is being performed at the Partial level — i.e., it isn’t entirely an ad hoc state.
Why a 3-level scale? Why not more? In my experience it is often extremely difficult to clearly define differences in levels when there are four or more of them — at least when you’re using qualitative descriptions. Three levels are much easier to differentiate, which makes the ratings more likely to be reliable and less open to debate. I’m also of the opinion that as long as you’re using qualitative rating “buckets”, you shouldn’t expect too much granularity. Fortunately, by measuring in two dimensions, each with a 3-level scale using the matrix above, you effectively achieve a 5-level rating scale for each sub-category (as shown in the matrix values above).
This two-dimensional structure also enables a bit richer analysis of an organization overall. Not only can you say things like, “20% of the subcategories are rated at a Level 4 condition” (the combination of claimed capability and confidence), but you can also articulate an organization’s ability to substantiate its conditions, which I would submit is a strong measure of maturity. In other words, an organization with an average Sub-Category Rating of 3.6 but an average Confidence rating of 1.8, is to be less trusted than an organization with the same average Sub-Category rating but a higher average Confidence rating (e.g., 2.3). The first organization simply can’t defend its claims as reliably as the second one can.
And for those in the audience who gasp at my use of math on ordinal scales (which is typically a very bad idea), averaging is one of the few mathematical functions you can use without being guilty of first degree analytic heresy (it’s more of a misdemeanor). Just keep in mind that averaging tends to leave out a lot of important information; minimums, maximums, and distribution shapes for example.
BTW — this two-dimensional rating approach seems to work well with any control or capability-oriented framework, like the FFIEC CAT, PCI, etc. Simply replace “sub-category” with whatever control or capability element being evaluated.
Strong/partial/weak compared to what?
In its simplest state, the definitions for Strong, Partial, and Weak can be very high-level. For example:
- Strong: The sub-category is both highly effective and has been implemented throughout most, if not all, of the organization
- Partial: The sub-category is either highly effective but implemented across only a minority of the organization, or is in place throughout the organization but is marginal in its efficacy
- Weak: The sub-category has either not been implemented at all, or is partially implemented and marginally effective
Obviously, this still leaves room for subjective judgment, particularly when it comes to “highly” effective versus “marginally” effective, and “most” versus “minority”. Still, I’ve found these definitions to be clear enough (and coarse enough) to use without spending too much time wrangling over whether a sub-category is one thing versus another, and it’s easy to document the rationale behind the choice that’s made. It’s also generic enough to reasonably apply to any of the sub-categories.
One interesting challenge with qualitative/ordinal scales is that InfoSec practitioners can be extremely self-critical. It isn’t unusual for an organization’s InfoSec team to rate a sub-category as Partial or Weak, only to have an external third party (e.g., an external auditor or regulator) say, “Well, compared to everyone else you’re Strong.”, which is a relative comparison to the industry. This is actually an important concern for at least a couple of reasons:
- It’s easy for an InfoSec team to rate the organization in one way (more critically, let’s say) and have an external entity rate it more favorably, which can seed in management’s mind that the InfoSec team’s judgment is biased or suspect (sound familiar?). In many cases, too, the more favorable rating is what management will choose to believe, regardless of whether it’s accurate.
- It begs the question of which is most appropriate; absolute efficacy or relative efficacy. Relative efficacy can be misleading and provide a false sense of security — i.e., the fact that every other organization stinks at a sub-category but one particular organization stinks less, doesn’t alter the fact that that organization still stinks at it. I believe absolute efficacy is the more truthful basis for measurement. Regardless, without consistency and clarity on this consideration, effective benchmarking is a pipe dream.
There is a way to make this 3-level scale more objective, but it involves a lot of work, both up-front and potentially over time. Essentially, for each sub-category you have to define specific, objective characteristics for each of the three levels. Let’s look at “Detected event analysis” as an example:

Clearly, this still has a certain amount of subjectivity involved — like what constitutes “well-defined” and “up-to-date”. Nonetheless, it provides better clarity than simply “Highly effective,” etc.
Defining criteria like these for roughly a hundred NIST-CSF sub-categories would be a non-trivial exercise. It also would probably be difficult to get consensus on what these detailed criteria should be (and I can easily imagine that a lot of people will have ideas for improving my example). In addition, the criteria would have to be reviewed and updated periodically to capture improvements in technologies and techniques.
Other benefits of fleshing out the sub-categories at this additional level of detail would include:
- Help to identify redundancies and other problems with the framework
- It would probably make performing assessments go much faster because you wouldn’t have to go look up Cobit, ISO, and whatever other references and then decide how to interpret/apply them.
Yes, I do realize that one of the “benefits” of the CSF not having clearly defined criteria and instead simply referencing existing standards, was that it was less prescriptive and more flexible. I guess from my perspective the framework becomes something of a middleman then, and it doesn’t provide the clarity and consistency of measurement that I believe could be some of it’s greatest potential benefits.
Having confidence
The Confidence scale is a little more straight forward. Essentially, the definitions boil down to:
- Validated thru testing: An independent party has evaluated the capability more than once, and at least once within the past year, and found it to align with the rating. For example, a claim of Strong has been made regarding data leakage protection, and Internal Audit (or another independent source) has formally evaluated the capability and found no deficiencies that would disqualify it from a Strong rating.
- Substantiated by Policies and/or Processes: The organization has formally defined expectations regarding the capability (usually thru policies and/or processes) that help to reduce the likelihood of the capability being ineffective or not meeting expectations.
- Unsubstantiated: There are no formal policies or processes that formally establish expectations for this capability, which increases the likelihood of it being ineffective.
Limitations
In order for any assessment framework to be reliable and defensible, the measurement scale needs to meet at least a few requirements:
- Scale definitions must logically align with what’s being measured (which is why the current NIST CSF tiers shouldn’t be used to measure its sub-categories)
- Scale definitions must be clear enough that they reduce the odds of misinterpretation
- The levels must provide meaningful differentiation (i.e., avoid too much granularity)
- The scale should accurately convey the nature or condition of what’s being measured (e.g., don’t use a binary yes/no measurement for non-binary conditions)
- If benchmarking is considered to be an important potential benefit from a framework like the NIST CSF, another critical requirement is scale standardization
Effective benchmarking and prioritization will require quantifying risk
Regardless, although it’s obviously important to use a well-defined scale to rate sub-categories, we still have to keep in mind that what we’re measuring is capabilities.
Yes, there is an implicit and logical assumption that better, more mature capabilities equate to less risk, but the framework gives us no way of knowing how much less risk, or whether the current or residual levels of risk are acceptable.
In order to achieve that level of intelligence, you need explicitly measure risk using an analytical model like FAIR, as described in the 4th post in this series.
If you missed my previous posts on NIST CSF & FAIR, please read parts one, two, three and four.

-squared-1.png)
.png)



