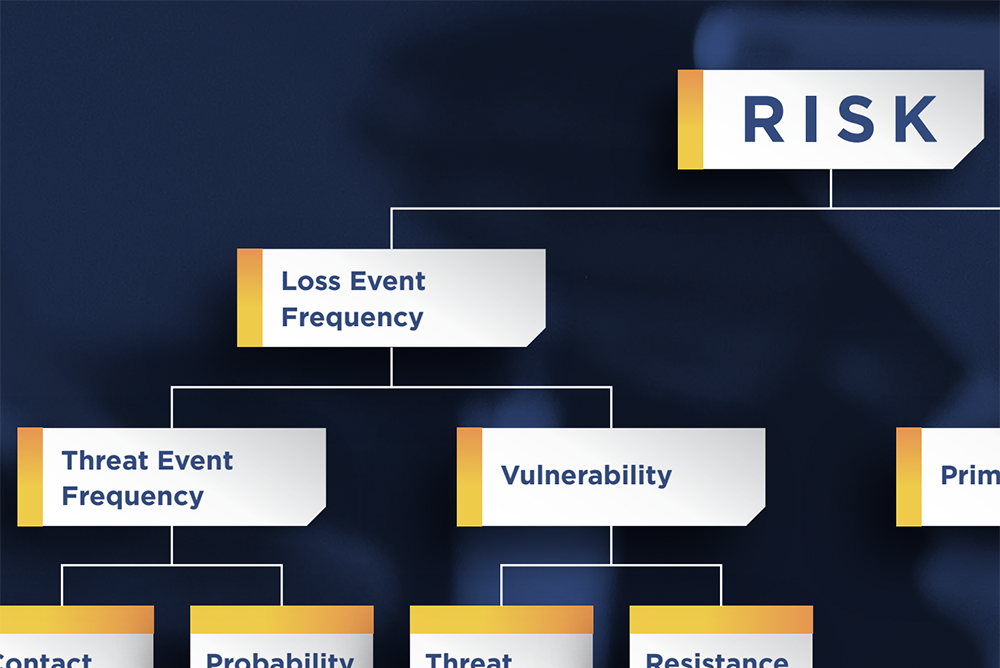
Guides & Tips What Is Cyber Risk Quantification (CRQ) and How Does It Help Risk Management Decisions?
FAIR Jack Jones Rebuts ‘FAIR Fatigue’, an Article Filled with Misrepresentations of Factor Analysis of Information Risk (FAIR), the Standard for Risk Quantification
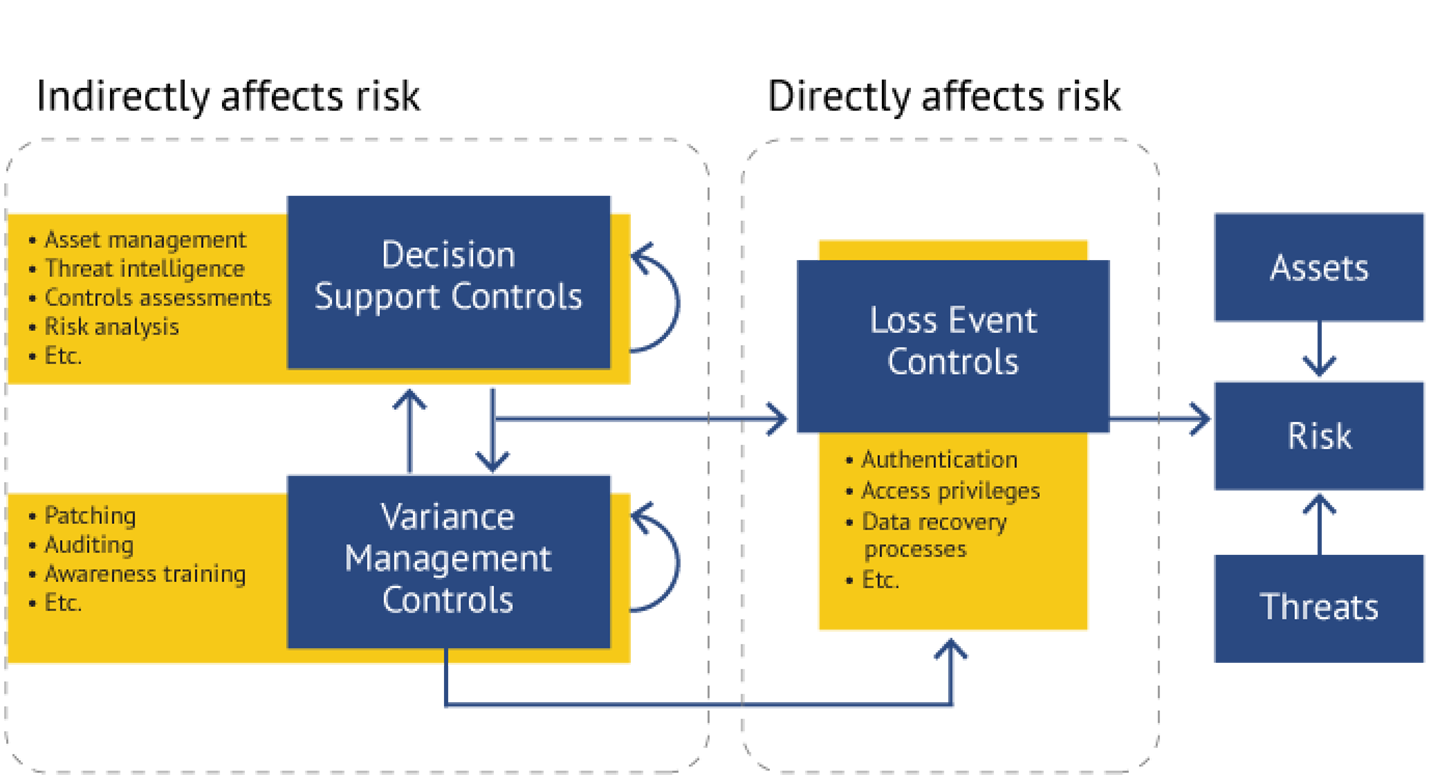
FAIR-CAM Study Finds Employees Will Violate Security Policy to Get Their Work Done – FAIR-CAM Helps to Solve the Problem
Jack Jones How Cyber Risk Management Is Like Buying a Bike for Your Daughter – Understanding the FAIR Controls Analytics Model (FAIR-CAM)