FAIR Summer Book Club 2020 FAIR Institute Summer Book Club Final Meeting - All 6 Chapter Guides to the FAIR Book Are Right Here
FAIR Summer Book Club 2020 FAIR Institute Summer Book Club Part 5 – Reading the FAIR Book Together – This Week: Controls and Common Mistakes
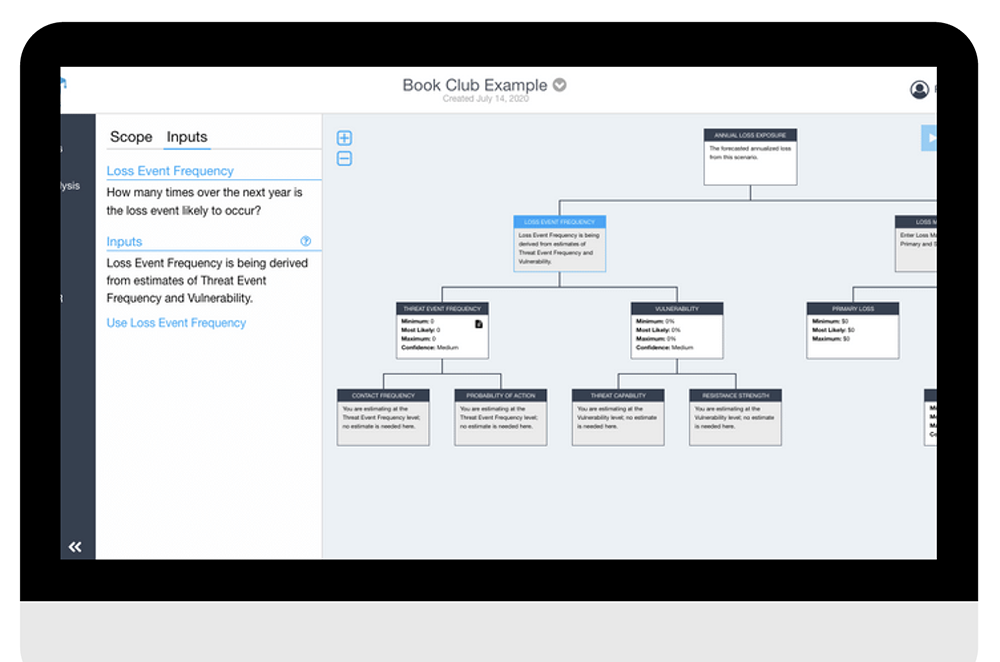
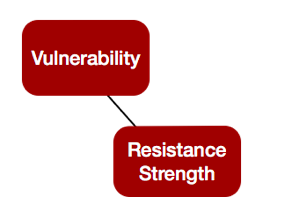
FAIR Summer Book Club 2020 FAIR Institute Summer Book Club Part 4 – Reading the FAIR Book Together – This Week: A Walk through a Sample Risk Analysis
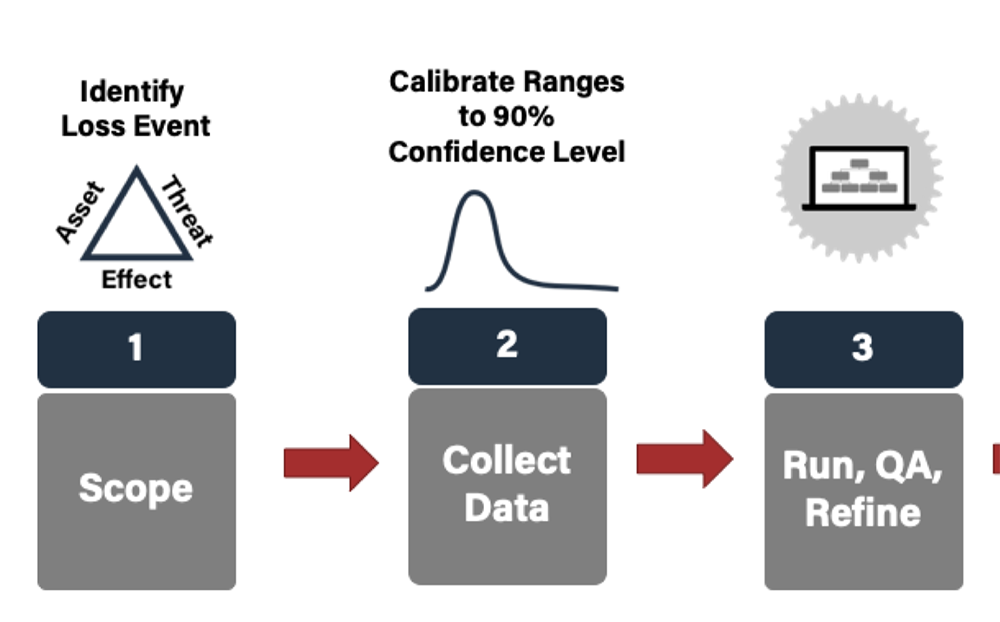
FAIR Summer Book Club 2020 FAIR Institute Summer Book Club Part 3 – Reading the FAIR Book Together - This Week: Analysis Process and Results
FAIR Summer Book Club 2020 Introducing the FAIR Institute Summer Book Club – Let’s Read & Discuss the FAIR Book Together